
Python
❏ 参考書


≫ 8-1 Seleniumのインストール
◎ Chrome用WebDriverのダウンロード
|
◯ Chromeブラウザのバージョン確認 chrome://settings/help |

|
◯ Chrome用WebDriverのダウンロード https://googlechromelabs.github.io/chrome-for-testing/#stable |

ダウンロードファイル
chromedriver-win64.zip
|
◯ ダウンロードファイルのバージョン確認 chromedriver.exeをダブルクリック |
|
◯ プログラムフォルダー構成 |

≫ 8-2 ブラウザを操作する
◎ ブラウザを起動する

|
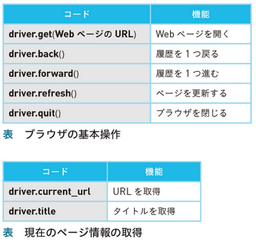
◯ driver = webdriver.Chrome(service=service) driverがchromedriver.exeへの指示を中継する ◯ WebDriverからブラウザを起動した場合 「chromeは自動テストソフトウェアによって起動されています。」と表示される ◯ driver.quit() ブラウザを閉じる |
|
注意 :TypeError: WebDriver.init() got an unexpected keyword argument 'executable_path'が出る場合 リンク
◎ Webページを順に遷移して履歴を遡る
|
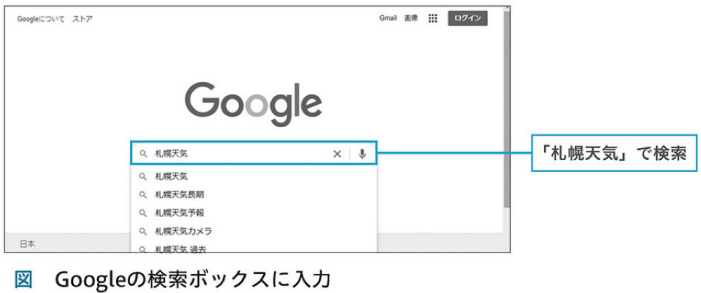
◎ テキスト入力、キー入力、クリック操作

|
◯ 要素.send_keysで送信する特殊キー Keys.ENTER Keys.SHIFT Keys.DELETE Keys.CONTROL ◯ 要素.send_keys("札幌天気" + Keys.ENTER) テキストと特殊キーは「+」で一緒に入力できる ◯ 要素.click() ボタンやリンクをクリック ◯ driver.find_element() Webページから要素を特定するには表示中のWebページから検索する ◯ driver.implicitly_wait(10) 条件に合う要素がすぐに見つからない場合の待ち時間 インターネット上には要素を後から読み込むWebページもあるので、見つからない場合の待ち時間を設定 |
|
≫ 8-3 Selenium IDEでブラウザ操作を記録
◎ インストール

|
1. ブラウザ右上 > Chromeの設定 > 拡張機能 > Chrome ウェブストアにアクセス 2. 「Selenium IDE」で検索 3. 検索結果からSelenium IDEを選択 4. 「Chromeに追加」をクリック |
◎ ブラウザ操作を記録


|
1. ブラウザ右上 >拡張機能 > Selenium IDEを選択
2. 起動画面から「Record a new test in a new project」を選択
3. 起点にするWebページのURLを入力する画面が表示される 4. 入力したURLが別ウィンドで起動されるので記録したい操作を行う 例 ①「札幌転記」を入力 ②Enterキーを押下 ③画面遷移先で「降水確率」をクリック 別ウィンドで開いているSelenium IDEで録画中止ボタンをクリック テスト名を入力(例 sapporo-tenki)してOKを押下するとサイドバーに登録される
|
◎ 記録したブラウザ操作をPythonに書き出す


|
1.Selenium IDEのサイドバーのテスト名を右クリックして「Export」をクリック 2. 言語を選択する画面で「Python pytest」を選択して「EXPORT」をクリック 3. 適当な名前で保存。IDLEで確認 |
≫ 8-4 Webページから情報を読み取る
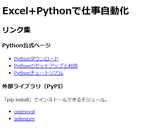
◎ 要素の特定に欠かせない2つの属性
◯ グローバル属性
・属性には特定要素で用いる属性と、すべての要素で使用できるグローバル属性がある
・グルーバル属性の中でも「id属性」「class属性」はWebページ作成で頻繁に使用される
・pythonで要素を特定するときに欠かせない属性
|
◯ id属性 ・1つのページ内で同じ値のid属性は使えない ・id属性を使えばページで唯一の要素を特定できる ・例 <div id="python"> ◯ class属性 ・要素にデザインを適用するための分類名として用いられる ・ページ内の複数のパーツに同じデザインを適用できるように、同じclass属性の値は重複して使える ・値をスペースで区切ることで1つの要素に複数の値を指定できる ・例 <div class="footer list"> |
◎ HTMLタグの種類
◯ inputタグ
・name属性を利用してSeleniumで要素を特定
|
◯ divタグ ・id属性で特定のコンテナを特定 |
◎ Webページから情報を読み取る方法



|
◯ 要素を検索する find_element、find_elements
◯ 検索方法 By.〇〇の形でタグ名、属性の値、cssセレクタなどを指定できる
◯ 検索した要素から情報を読み取る 例えば下記a要素に対してテキストの”Python”や、属性「href」の 値の"https://www.python.org"を取得できる <a href="https://www.python.org">Python</a>
|
|
検索した要素の中から、さらに要素を検索することで「要素を絞り込む」ことができる |

|
◯ id_python = driver.find_element(By.ID,"python") 「id属性」が"python"の親要素を検索 ◯ links = id_python.find_elements(By.TAG_NAME,"a") 親要素の中のタグ名「a要素」の全てを検索 ◯ for link in links: 検索結果のリストが代入されたlinksをループ |
|
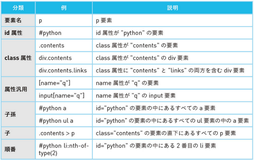
◎ CSSセレクタを用いた柔軟な検索方法
|
◯ find_elements(By.CSS_SELECTOR, "#python a") 前述のid属性:"python"の中の全てのa要素を絞り込むには、「#python a」と書くだけで済む
|
|
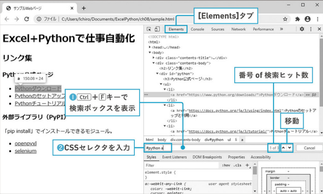
◎ ブラウザのツールを用いてCSSセレクタを調べる


|
◯ Chromeデベロッパーツールを表示 リンクの個所を右クリックして「検証」を選択
◯ ChromeデベロッパーツールのElementsタブ 要素にマウスポインターを合わせるとWebページの該当する部分に網掛けが 連動して表示される。Python公式ページに関するリンクの「a要素」がid属性 "Python"の要素の中にあるのがよく分かる
◯ [Elements]タブの検索機能 [Elements]タブでCtrl+Fキーを押すと検索ボックスが表示される CSSセレクタ(例 #Python a)と入力すると条件に一致する要素を検索できる 検索ボックスの右側にはヒット件数が表示される、上下ボタンで移動可能 |
≫ 8-5 実際のWebページから情報を読み取る
|
新着情報の最新日付の要素の確認手順 |
|
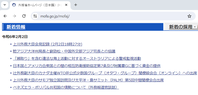
① Webページを開く https://www.mofa.go.jp/mofaj/ (外務省トップ)
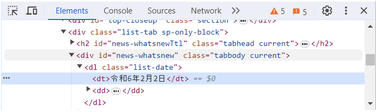
② 要素を確認したところで検証を選択 1) "令和6年2月2日"で右クリック 2) 「検証」を選択 3) Chromeデベロッパーツールを表示
③ Elementsタブで要素を確認 id属性が”news-whatsnew”のdiv要素の中にdt要素が並んでいて、 その中の一番目が最新日付に該当
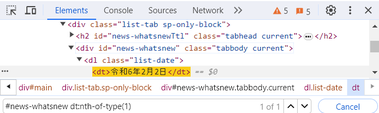
④ n番目のdt要素を取得 1) Ctrl +Fキーで検索ボックスを表示 2) 指定id属性内の1番目のdt要素を取得するCSSセレクタを入力 #news-whatsnew dt:nth-of-type(1)
|
|
新着情報の新着情報の要素も同様手順で確認 |
|
n番目のdd要素の中の全てのli要素のa要素(リンク)を取得 1) Ctrl +Fキーで検索ボックスを表示 2) 下記CSSセレクタを入力すると7か所ヒットする #news-whatsnew dd:nth-of-type(1) li a
※ #news-whatsnew dd:nth-of-type(1) ul li a でも同じ結果が得られる |

◎ 要素から情報を読み取りEXCELに出力
|
◯ driver.find_element(By.CSS_SELECTOR, "#news-whatsnew dt:nth-of-type(1)") 指定id属性内の1番目のdt要素を取得
◯ driver.find_elements(By.CSS_SELECTOR, "#news-whatsnew dd:nth-of-type(1) li a") 指定id属性内の1番目のdd要素の中の全てのli要素のa要素(リンク)を取得
|
|
≫ 8-6 Webから情報収集を自動化する
◎ ExcelのURLリストから自動で巡回する

◯ driver.save_screenshot(ファイル名)
開いているページのスクリーンショットを保存する
|